

Featured research
ES&T | Using Environmental Mixture Exposure Triggered Biological Knowledge-Driven Machine Learning to Predict Early Pregnancy Loss
Recently a research team led by Dr. Bin Wang at Peking University, in collaboration with multidisciplinary teams in domestic and international institutions, has for the first time integrated human environmental mixture exposure with biological knowledge network to develop a machine learning model for early pregnancy loss (EPL) in women undergoing in vitro fertilization and embryo transfer (IVF-ET). The established model enables accurate prediction of EPL while providing insightful biological interpretations for EPL driven by environmental mixture exposures (Fig 1).
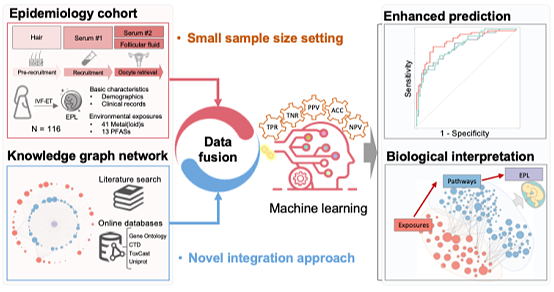
Fig 1 Graphical abstract
Manuscript type:Article
First author:Mengyuan Ren(Peking University)
Corresponding author:Bin Wang (Peking University)
Journal:Environmental Science & Technology,IF2024 = 11.3
Manuscript information:
Mengyuan Ren, Tianxiang Wu, Han Zhang, Shuo Yang, Lu Zhao, Lili Zhuang, Qun Lu, Xikun Han, Bo Pan, Tiantian Li, Jingchuan Xue, Yuanchen Chen, Michael S. Bloom, Mingliang Fang, Bin Wang*. Using Environmental Mixture Exposure Triggered Biological Knowledge-1 Driven Machine Learning to Predict Early Pregnancy Loss. Environmental Science & Technology, 2025, https://doi.org/10.1021/acs.est.5c05389
Full text link:https://pubs.acs.org/doi/10.1021/acs.est.5c05389

It’s reported by World Health Organization (WHO) that the estimated global prevalence of infertility is 17.5%, which has become an important reproductive health issue. Particularly in China, the annual number of newborns has declined rapidly in recent years, partly due to infertility. Although in vitro fertilization and embryo transfer (IVF-ET) has been widely applied as a dominant treatment for infertile couples, a considerable proportion of patients still fail to achieve pregnancy, leading to enormous economic and social burdens to couples and their families. Increasing evidence highlights the substantial contributions of environmental exposures to reproductive dysfunction related to infertility. However, due to the complex correlation patterns, interactions, and mixture effects among pollutants in the real-world setting, conducting systematic studies remains a major challenge. To address these, it is critical to identify sensitive biomarkers and to develop robust prediction models to evaluate the risk of early pregnancy loss (EPL) during IVF-ET. The rapid development of machine learning (ML) algorithms provides a promising solution toward this goal, helping to achieve early diagnosis, securing a time window for interventions, and thereby reducing harm to both women and embryos. To date, some studies have used clinical and biochemical records to develop prediction models for IVF-ET outcomes and EPL. Even so, studies that incorporate environmental exposures into EPL prediction models remain scarce, despite numerous evidence linking these exposures to IVF-ET outcomes. In addition, existing models have difficulty revealing the complex mechanisms underlying mixture exposures and face limitations in biological interpretability.
The advancement of omics technologies provides a feasible approach to understand the biological mechanisms connecting environmental pollutants and EPL. Despite that, large-scale omics studies are costly in both time and funding. As an alternative, Biological Knowledge Graph-driven Networks (BKGN) can efficiently connect chemical exposures with adverse health outcomes through known and validated targets and pathways from high-quality databases. Our previous work established a BKGN for IVF-ET outcomes, demonstrating its ability to systematically explain how environmental exposures contribute to implantation failure. With its powerful ability to characterize biological network information, BKGN can also be applied to predicting protein–ligand interactions, identifying drug therapeutic targets, and evaluating chemical toxicity. These applications underscore BKGN’s unique advantage of simultaneously improving model performance and providing clear biological interpretation. Regarding chemical substances, applications of BKGN have mainly focused on toxicity prediction and exposure risk assessment, while its use in disease risk prediction remains limited. Moreover, obtaining high-quality data often requires long-term follow-up and costly experimental analysis, which frequently results in limited sample sizes. We believe that, within the BKGN framework, small-sample learning can partially address these challenges. Nevertheless, integrating exposure-based BKGNs with population-level environmental health studies, and assessing the biological disturbances caused by chemical exposures in the context of biological networks, still poses difficulties.
This study developed a framework that leverages individual-level environmental exposures with pollutant-specific BKGN in machine learning model. Feature engineering was utilized across environmental exposure scenarios, and a two-stage feature selection strategy was employed to identify key exposures and pathway features. Finally, the model performance was evaluated and compared. The overall study design is shown in Fig 2. Previous studies (including our own) have found that metal(loid)s and per- and polyfluoroalkyl substances (PFAS) were associated with EPL risk. Recent research also highlighted the joint effects of metals and PFAS on human health, such as cardiovascular disease and depression. Therefore, this study used these pollutants as examples of target mixtures to test the performance of the proposed framework. This study aimed to leverage mixture exposures and BKGN to enhance the prediction of EPL risk among women undergoing IVF-ET. Through the developed model, they identified key environmental exposures and related biological pathways, thereby providing mechanistic insights into potential biological processes.
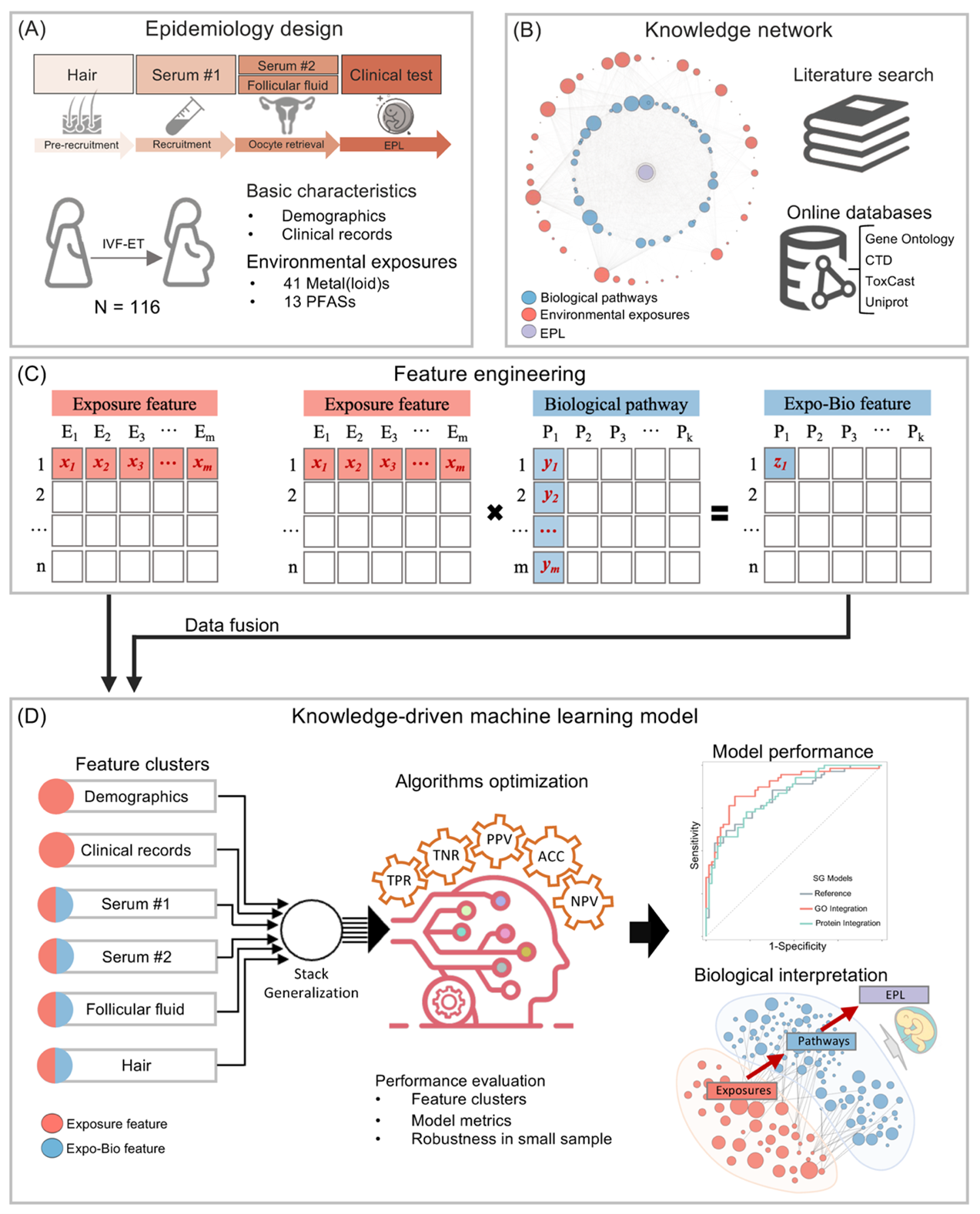
Fig 2: Study design. This study established a machine learning framework driven by integrating environmental exposures with knowledge graph–driven biological networks (BKGN). Feature engineering was conducted across different environmental exposure scenarios. A benchmarking approach was used to determine the optimal algorithm. Subsequently, a two-stage feature selection strategy was applied to identify key environmental exposures and pathway features. Finally, a biologically interpretable BKGN was constructed using a stack generalization (SG) approach, and the model performance was evaluated and compared.
Main findings:
(1) The environmental mixture exposure scenario is extremely complex, necessitating the construction of a BKGN to represent the “Exposure–Biological target–Early pregnancy loss” network: In this study, various environmental exposures were significantly highly-correlated, suggesting the complexity of real-world mixture exposure scenarios. This study constructed two BKGNs: an “Exposure–Gene Ontology (GO)–Disease” network and an “Exposure–Protein–Disease” network, which further revealed the intricate relationships between environmental mixtures and biological targets/pathways (Fig 3). The BKGN was then transformed into a Boolean matrix, and biologically informed pathway features were constructed using feature engineering strategy, combined with individual-level environmental mixture exposure data.
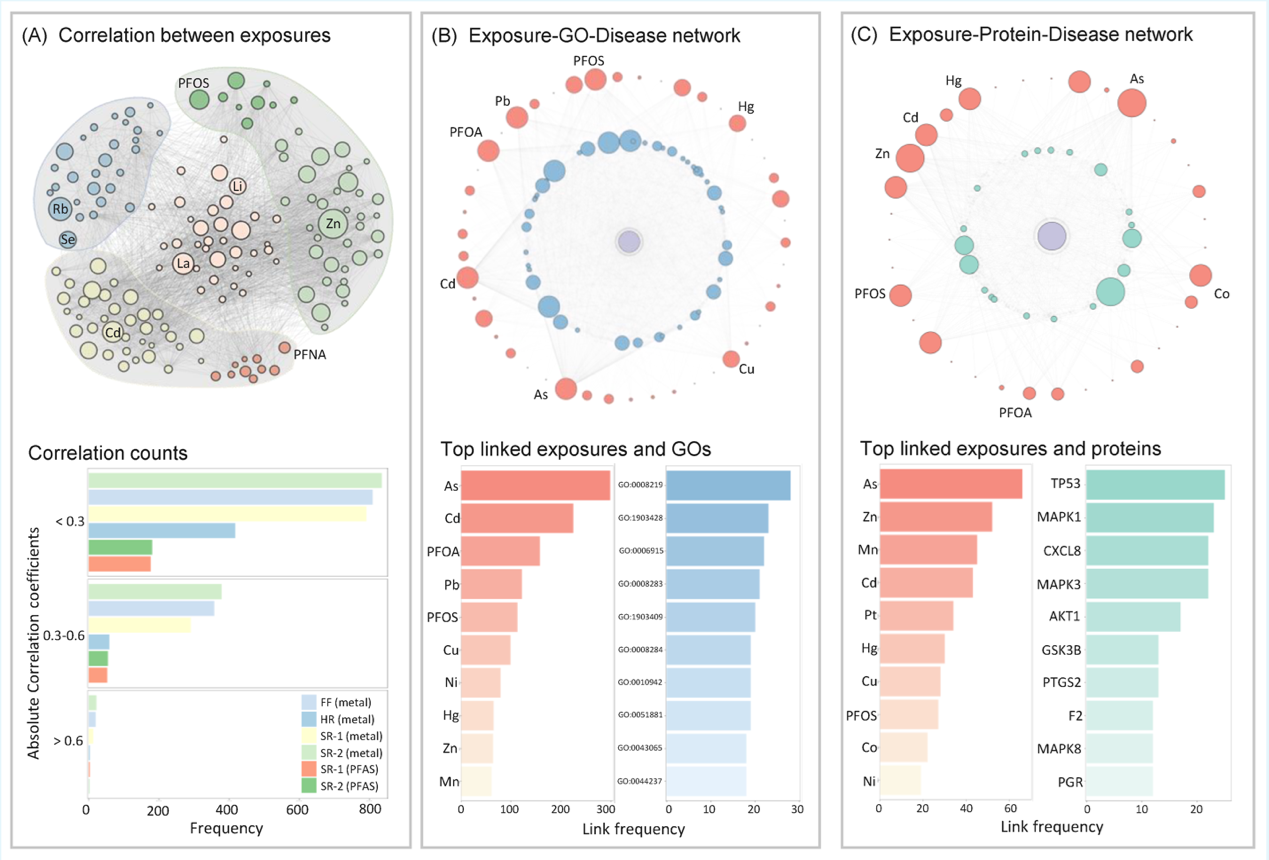
Fig 3: Environmental exposure features and the “Exposure–Pathway–Disease” network. (A) Correlations between environmental exposures and early pregnancy loss (EPL). The size of each node represents the –log₁₀(P) value of the Spearman correlation between the exposure and EPL; edges represent statistically significant correlations between exposures (P < 0.05). (B) Exposure–Gene Ontology (GO)–Disease Network. Edges represent links between exposures, GO pathways, and EPL. Node size indicates the number of edges connected to each node (exposure or GO pathway). (C) Exposure–Protein–Disease (EPD) Network. Edges represent connections between exposures, protein targets, and EPL. Node size indicates the number of edges connected to each node (exposure or protein). Only the top ten exposures/GO terms/proteins with the highest number of connections are displayed.
(2) Select optimal algorithm via benchmarking strategy:
This study adopted 5-fold cross-validation combined with a benchmarking approach to evaluate and compare the overall performance of several commonly used machine learning algorithms across different exposure scenarios and model sets (including the GO-integrated model, the protein-integrated model, and the reference model) (Fig 4). Overall, the Extreme Gradient Boosting (XGBoost) algorithm demonstrated both robustness and strong predictive performance. As a result, XGBoost was selected as the algorithm for downstream modeling, including feature selection for exposures and biological pathways under different exposure scenarios, as well as final model construction.
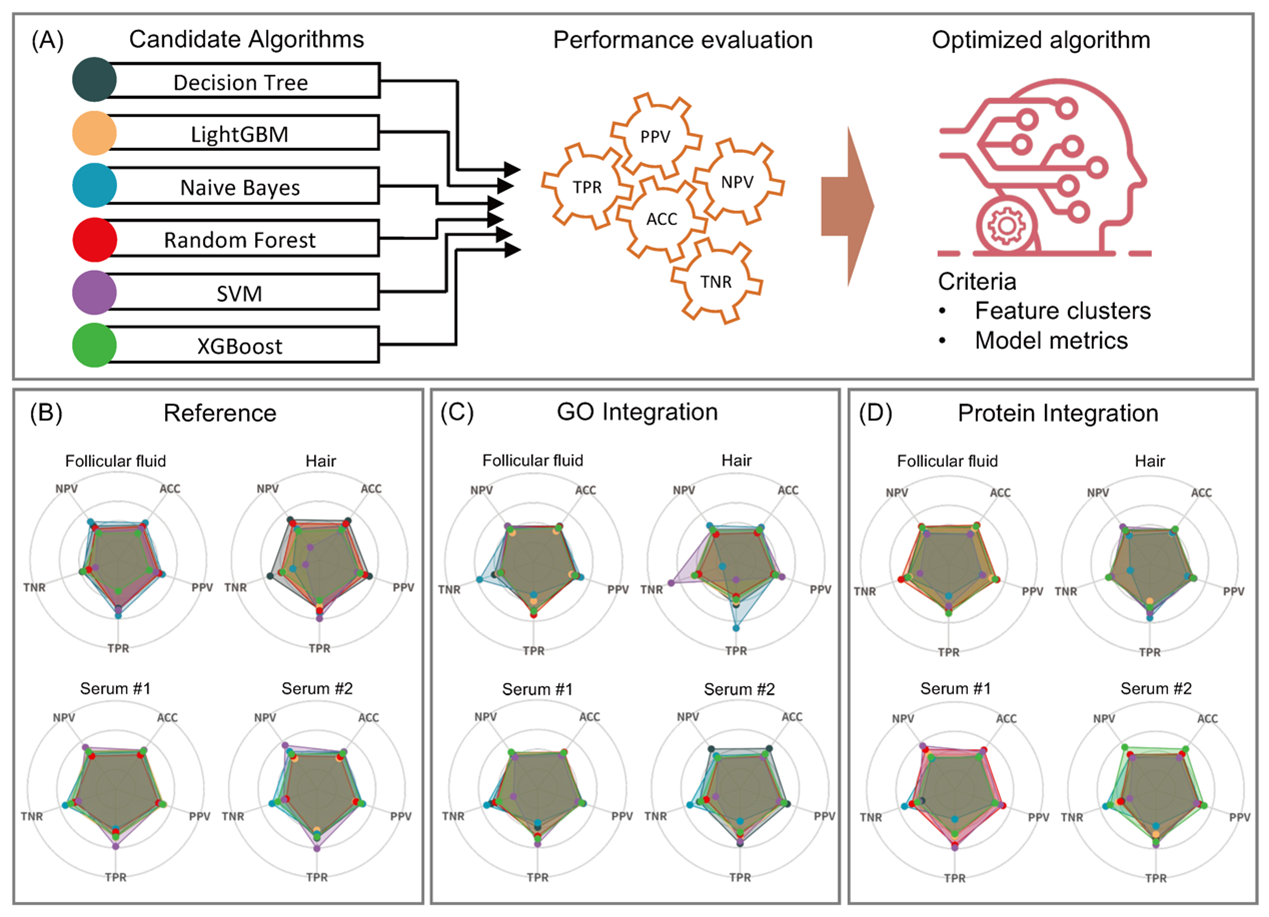
Fig4: Benchmarking-based algorithm selection. This study evaluated six candidate algorithms—Decision Tree, Naive Bayes, Support Vector Machine (SVM), Random Forest, Extreme Gradient Boosting (XGBoost), and Light Gradient Boosting Machine (LightGBM)—to assess and compare their overall model performance under different exposure scenarios and model sets. Two knowledge-driven models were proposed: the GO-integrated model and the protein-integrated model. A reference model without BKGN data was also constructed for comparison. Model performance was evaluated using five metrics: accuracy (ACC), true positive rate (TPR), true negative rate (TNR), positive predictive value (PPV), and negative predictive value (NPV). Theoretically, the selected algorithm should demonstrate consistently strong performance across different exposure scenarios and model sets.
(3) Construction of a BKGN-based EPL prediction model: This study employed a Stacked Generalization (SG) strategy to integrate environmental mixture exposure scenarios, thereby constructing a BKGN-ML model that closely reflects real-world complexity. The results showed that, compared to the reference model (AUC = 0.819), the predictive performance of the GO-integrated model was significantly improved (AUC = 0.876). Robustness analysis further confirmed the superior predictive performance of the GO-integrated model, especially in small-sample settings. More importantly, the BKGN-ML model offers biological interpretability. For example, the study found that, in complex exposure scenarios, serum selenium and chromium levels on the day of oocyte retrieval made substantial contributions to EPL risk. The underlying biological mechanisms may involve processes such as cell population proliferation and differentiation, apoptosis, and inflammatory responses (Fig 5).
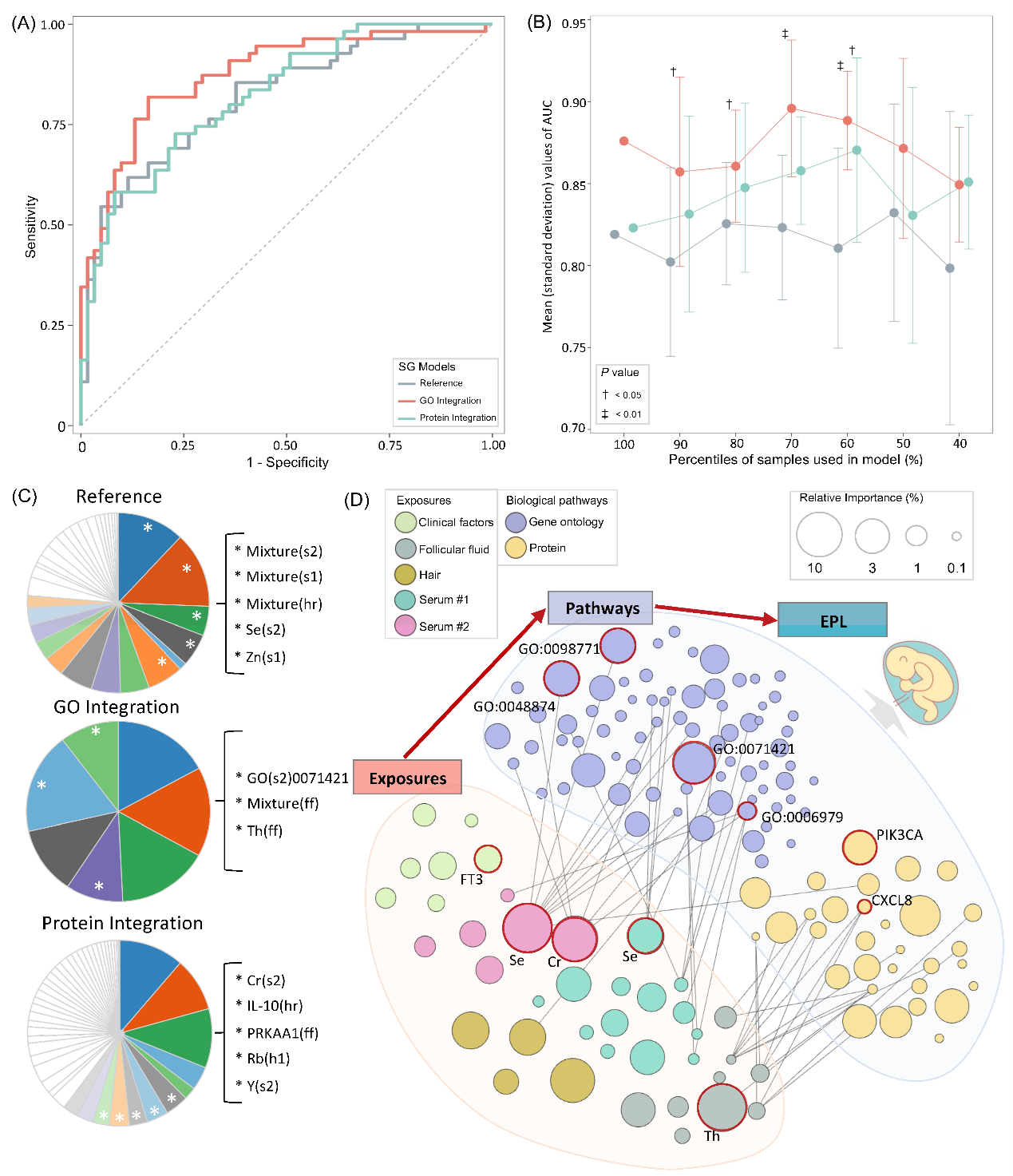
Fig 5: Knowledge-driven stacked generalization (SG) model for predicting early pregnancy loss (EPL). (A) Two knowledge-driven models were constructed and compared with the reference model, using the area under the curve (AUC) as the evaluation metric. (B) The average (standard deviation) AUC values of different SG models under 10-fold bootstrapped subsamples. The X-axis represents the percentage of each subsample relative to the full dataset (N = 116); the Y-axis and plotted points represent the mean AUC values, with error bars showing the standard deviation. †: P < 0.05; ‡: P < 0.01. (C) Features selected in the SG model, including ensemble prediction features from the base models as well as originally identified features from the base models. For clarity, only top-ranking features are color-highlighted and annotated with text and asterisks. (D) Biological interpretation based on the knowledge-driven model. Each node represents a feature identified by the SG model; node size reflects the relative importance of the feature, and the connecting lines represent known relationships between features as encoded in the BKGN.
Strengths and innovations:
1. This study was conducted based on an existing prospective IVF-ET cohort of women, with longitudinal collection of hair, serum, and follicular fluid samples during both the ovarian stimulation phase and oocyte retrieval. This cohort provided comprehensive exposure profiles with a clearly defined temporal sequence.
2. Leveraging the EBIO module of the “ExposomeX” platform, we constructed a BKGN for EPL, comprehensively mapping the landscape of biological disturbances triggered by environmental exposures.
3. For the first time, we innovatively integrated BKGN-derived information into individual-level exposure profiles and developed a BKGN-based machine learning framework. The advantages of this framework include:
· Providing biologically insights into the complex and quantitative effects of environmental exposures on EPL risk at low cost and with robust performance even under small-sample conditions;
· Prioritizing candidate biomarkers under complex exposure scenarios to support future biological validation and experimental studies;
· Serving as a pioneering application of BKGN in interdisciplinary research, offering new solutions to enhance model performance, especially in the field of environmental health.
Summary and implications:
This study presents a scalable and interpretable analytical approach to link real-world chemical mixtures with adverse reproductive outcomes. By integrating biological knowledge-based graphs with exposure data, our framework reveals how environmental pollutants—such as PFAS and metal(loid)s—may disrupt early pregnancy processes. The findings underscore the importance of developing “mixture-aware” toxicological models in reproductive epidemiology and support the formulation of targeted regulatory strategies to mitigate the reproductive health risks posed by complex environmental exposures. The BKGN model identified key exposures (e.g., serum selenium and chromium) and elucidated associated biological disturbances related to EPL, including inhibited cell proliferation, and triggered cellular changes. These findings lay a foundation for future validation studies aimed at confirming and further characterizing previously unrecognized mixture effects. Meanwhile, the BKGN model integrates individual-level mixture exposure profiles with chemically specific biological information derived from gene ontology annotation and protein interactions. It demonstrates robust predictive accuracy even under small-sample conditions, highlighting the new potential of BKGN and its significant advantages in enhancing both model performance and biological interpretability. This novel approach holds broad application prospects, particularly in environmental epidemiology studies with limited sample sizes under evidence-based "exposome–biological network" research contexts.
Acknowledgments:
We thank the Environment and Human Health Working Group of the China Cohort Consortium (http://chinacohort.bjmu.edu.cn) for providing a collaborative platform.
Author introduction:

Bin Wang
Associated Professor/Researcher, Vice Dean, Institute of Reproductive and Child Health, School of Public Health, Peking University
Dr. Bin Wang’s primary research focuses on environmental health, exposome big data, and artificial intelligence. His work employs multidisciplinary approaches to uncover the impacts and mechanisms of environmental exposures on reproductive health and to construct health risk assessment models. To date, he has led four projects funded by the National Natural Science Foundation of China (General and Young Scientists Programs) and served as a key investigator in three National Key R&D Projects. As first or corresponding author, he has published 65 papers in leading international journals, including Environmental Health Perspectives, Environmental Science & Technology, and The Innovation (H-index = 45; >6,500 citations). He currently serves as the leader of the "Environment and Human Health" working group of the Chinese Cohort Consortium Sharing Platform, Associate Editor of Environmental Science & Technology and as an editorial board member of several prominent journals. He has received the Beijing University Experimental Technology Achievement Award (Third Prize), the Beijing Preventive Medicine Association Science and Technology Award (Second Prize), and recognition as an "Advanced Individual in the National Science and Technology System's Fight Against COVID-19". I have also constructed a large-scale data integrated analysis platform for exposure omics, introduced basic concepts, design, and technology for exposure omics research, provided two methods of webpage operation (www.exposomex.cn/) and R package (https://github.com/ExposomeX), and opened free access for researchers to promote the application research and discipline development of exposure science in human health research.

Mengyuan Ren, PhD
Postdoctoral Fellow, Rollins School of Public Health, Emory University, US
Dr. Mengyuan Ren’s research focuses on assessing reproductive health risks associated with human exposure to complex environmental pollutant mixtures. He specializes in developing risk assessment and predictive models based on multi-omics data. To date, she has published eight first-author papers in high-impact journals, including The Innovation (IF = 25.7), Environmental Science & Technology (IF = 11.3), and Environment International (IF = 9.7). He has also contributed as a team member to five major national research projects, including grants from the National Natural Science Foundation of China, the National Key R&D Program of China, and the Ministry of Science and Technology’s International Science and Technology Innovation Cooperation Program. Dr. Ren is a core developer of the ExposomeX platform (http://www.exposomex.cn/). He serves as a reviewer for several leading journals in environmental health, including Environmental Health Perspectives, Environmental Science & Technology, Environment International, Environmental Pollution, and Environment & Health. In 2024, she was recognized as a Top Peer Reviewer by Environmental Health Perspectives.